Designing 'Neuromorphic' Hardware To Make Software Operate Optimally
Creating hardware designed to make artificially intelligent software run more productively. JL
Matthew Hutson reports in ars technica:
As programmers create “neural network” software to run on regular
computer chips, engineers are also designing “neuromorphic” hardware
that can imitate the brain more efficiently. Combining convolutional nets with neuromorphic chips could lead to smarter cars and to
cellphones that efficiently understand our verbal commands—even when we
have our mouths full.
As the world’s great companies pursue autonomous cars, they’re essentially spending billions of dollars to get machines to do what your average two-year-old can do without thinking—identify what they see. Of course, in some regards toddlers still have the advantage. Infamously last year, a driver died while in a Tesla sedan—he wasn't paying attention when the vehicle's camera mistook a nearby truck for the sky.The degree to which these companies have had success so far is because of a long-dormant form of computation that models certain aspects of the brain. However, this form of computation pushes current hardware to its limits, since modern computers operate very differently from the gray matter in our heads. So, as programmers create “neural network” software to run on regular computer chips, engineers are also designing “neuromorphic” hardware that can imitate the brain more efficiently. Sadly, one type of neural net that has become the standard in image recognition and other tasks, something called a convolutional neural net, or CNN, has resisted replication in neuromorphic hardware.
That is, until recently.
IBM scientists reported in the Proceedings of the National Academy of Sciences that they’ve adapted CNNs to run on their TrueNorth chip. Other research groups have also reported progress on the solution. The TrueNorth system matches the accuracy of the best current systems in image and voice recognition, but it uses a small fraction of the energy and operates at many times the speed. Finally, combining convolutional nets with neuromorphic chips could create more than just a jargony mouthful; it could lead to smarter cars and to cellphones that efficiently understand our verbal commands—even when we have our mouths full.
Getting tech to learn more like humans
Traditionally, programming a computer has required writing step-by-step instructions. Teaching the computer to recognize a dog, for instance, might involve listing a set of rules to guide its judgment. Check if it’s an animal. Check if it has four legs. Check if it’s bigger than a cat and smaller than a horse. Check if it barks. Etc. But good judgment requires flexibility. What if a computer encounters a tiny dog that doesn’t bark and has only three legs? Maybe you need more rules, then, but listing endless rules and repeating the process for each type of decision a computer has to make is inefficient and impractical.
Humans learn differently. A child can tell dogs and cats apart, walk upright, and speak fluently without being told a single rule about these tasks—we learn from experience. As such, computer scientists have traditionally aimed to capture some of that magic by modeling software on the brain.
The brain contains about 86 billion neurons, cells that can connect to thousands of other neurons through elaborate branches. A neuron receives signals from many other neurons, and when the stimulation reaches a certain threshold, it “fires,” sending its own signal to surrounding neurons. A brain learns, in part, by adjusting the strengths of the connections between neurons, called synapses. When a pattern of activity is repeated, through practice, for example, the contributing connections become stronger, and the lesson or skill is inscribed in the network.
In the 1940s, scientists began modeling neurons mathematically, and in the 1950s they began modeling networks of them with computers. Artificial neurons and synapses are much simple than those in a brain, but they operate by the same principles. Many simple units (“neurons”) connect to many others (via “synapses”), with their numerical values depending on the values of the units signaling to them weighted by the numerical strength of the connections.
Artificial neural networks (sometimes just called neural nets) usually consist of layers. Visually depicted, information or activation travels from one column of circles to the next via lines between them. The operation of networks with many such layers is called deep learning—both because they can learn more deeply and because the actual network is deeper. Neural nets are a form of machine learning, the process of computers adjusting their behavior based on experience. Today’s nets can drive cars, recognize faces, and translate languages. Such advances owe their success to improvements in computer speed, to the massive amount of training data now available online, and to tweaks in the basic neural net algorithms.
Enlarge/ Of course Wikimedia has a CNN diagram that includes an adorable robot...
Wikimedia
Convolutional neural nets are a particular type of network that has gained prominence in the last few years. CNNs extract important features from stimuli, typically pictures. An input might be a photo of a dog. This could be represented as a sheet-like layer of neurons, with the activation of each neuron representing a pixel in the image. In the next layer, each neuron will take input from a patch of the first layer and become active if it detects a particular pattern in that patch, acting as a kind of filter. In succeeding layers, neurons will look for patterns in the patterns, and so on. Along the hierarchy, the filters might be sensitive to things like edges of shapes, and then particular shapes, then paws, then dogs, until it tells you if it sees a dog or a toaster.
Critically, the internal filters don’t need to be programmed by hand to look for shapes or paws. You only need to present to the network inputs (pictures) and correct outputs (picture labels). When it gets it wrong, it slightly adjusts its connections until, after many, many pictures, the connections automatically become sensitive to useful features. This process resembles how the brain processes vision, from low-level details up through object recognition. Any information that can be represented spatially—two dimensions for photos, three for video, one for strings of words in a sentence, two for audio (time and frequency)—can be parsed and understood by CNNs, making them widely useful.
Although Yann LeCun—now Facebook’s director of AI research—first proposed CNNs in 1986, they didn’t reveal their strong potential until a few adjustments were made in how they operated. In 2012, Geoffrey Hinton—now a top AI expert at Google—and two of his graduate students used a CNN to win something called the ImageNet Challenge, a competition requiring computers to recognize scenes and objects. In fact, they won by such a large margin that CNNs took over, and since then every winner has been a CNN.
Now, mimicking the brain is computationally expensive. Given that human brain has billions of neurons and trillions of synapses, simulating every neuron and synapse is currently impossible. Even simulating a small piece of brain could require millions of computations for every piece of input.
So unfortunately, as noted above, convolutional neural nets require huge computing power. With many layers, and each layer applying the same feature filter repeatedly to many patches of the previous layer, today’s largest CNNs can have millions of neurons and billions of synapses. Running all of these little calculations does not suit classic computing architecture, which must process one instruction at a time. Instead, scientists have turned to parallel computing, which can process many instructions simultaneously.
Today’s advanced neural nets use graphical processing units (GPUs)—the kind used in video game consoles—because they specialize in the kinds of mathematical operations that happen to be useful for deep learning. (Updating all the geometric facets of a moving object at once is a problem similar to calculating all the outputs from a given neural net layer at once.) But still, the hardware was not designed to perform deep learning as efficiently as a brain, which can drive a car and simultaneously carry on a conversation about the future of autonomous vehicles, all while using fewer watts than a light bulb.
A new paradigm
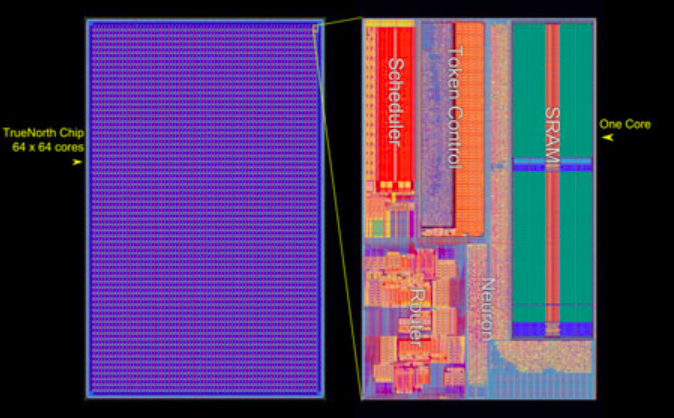
In the 1980s, engineer Carver Mead coined the term "neuromorphic processors" to describe computer chips that operate in a way loosely based on the brain. His work laid the foundation for this now-prominent field. While the term "neuromorphic" now applies to a wide variety of solutions, they all attempt to replicate neural networks in hardware, avoiding the information bottlenecks faced by traditional processors. Seeing the need for fast, efficient machine learning, in 2008 DARPA began awarding IBM and a corporate lab called HRL Laboratories millions of dollars to develop neuromorphic machines that can be scaled up easily. In 2014, IBM unveiled its TrueNorth chip in a cover article in Science. They've since developed systems based on TrueNorth with funding from the Department of Energy, the Air Force, and the Army.
The chip contains a million “neurons,” each represented by a group of digital transistors, and 256 million “synapses,” or wired connections between them. Two features make the chip much more efficient than traditional chips. First, like the brain, it communicates through “spikes,” or one-sized packets of information sent from one neuron to downstream neurons. Because it can communicate this way, the signals are simple (spike or no spike) and are transmitted only occasionally, when a neuron transmits a packet. Second, also like the brain, processing and memory are co-located—in the neurons and their synapses. In a traditional computer, a processing unit continually fetches information from separate memory areas, performs operations on it, and then returns the new information to memory when it’s done, leading to a lot of slow and wasteful communications.
The TrueNorth system is flexible, in that it can be programmed to implement networks of different sizes and shapes, and scalable, in that many chips can be tiled together easily. “It’s a new paradigm in scaling,” says Dharmendra Modha, IBM’s chief scientist for brain-inspired computing. Referring to the outer layer of the brain, he says, “this is how cortex itself scales its computation, essentially.” And the chip is efficient. For the Science paper, the IBM team used the chip to identify people, bicycles, and cars in a video of a street scene. A software simulation of TrueNorth running on a traditional microprocessor used 176,000 times as much power. “This is really a time where the whole technology is evolving and dramatically improving,” Modha says. "It will get better not by percentage points but by orders and orders of magnitude.”
A key part of the project was to develop not just the chip, but software to help program it. IBM created a simulator, a new programming language, and a library of algorithms and applications. The company then made these tools available to more than 160 researchers at academic, national, and corporate labs. “While the chip itself was a technological milestone, it’s part of an ecosystem that makes it usable, useful, and widely available to our partners,” Modha says.
Other researchers have commended the collaborative approach to achieving the chip’s potential. Tobi Delbruck, an engineer at the Institute for Neuroinformatics in Zurich, says, “TrueNorth as an entire ecosystem is a breakthrough in terms of building a usable large scale spiking neuromorphic accelerator.” Giacomo Indiveri, another engineer at the institute, which is a hub for neuromorphic research, says, “The effort that IBM is making in promoting this spike-based mode of signal processing and computation is extremely valuable for the neuromorphic engineering community.”
But the design of TrueNorth was finalized in 2011, and the CNN revolution didn’t happen until the 2012 ImageNet Challenge, leading some to question whether TrueNorth could handle these new networks.
At first look, training a deep convolutional net seems impossible because of what’s called the “credit assignment problem.” With many layers of many neurons and synapses, how do you know which elements are most responsible for a given mistake and need to be changed during learning? With millions or even just dozens of synapses, you can’t change them all in every possible combination and see what works best; even if each synapse has just 10 possible strengths and there are just 100 synapses, that’s googol combinations.
So CNNs use a learning method called backpropagation. Each time the network guesses something incorrectly, the difference between its guess and the right answer is calculated. The backpropagation algorithm looks at each neuron in the final layer and calculates how much a change in that neuron’s output would reduce the overall error. From there, it steps backward and for each of those neurons it calculates how much a change in the strength of each incoming synapse would reduce the network’s overall error. And so on, back through all the neurons and synapses. It then knows
at least whether each synaptic strength should be increased or decreased. So it adjusts each weight slightly in the right direction. It calculates a new error using these new weights and repeats the process. Slowly, after many steps, the error decreases in a process called gradient descent.
Initially TrueNorth was thought to be incompatible with backpropagation. That’s because gradient descent requires making tiny adjustments to weights and seeing tiny improvements. TrueNorth, on the other hand, maximizes its efficiency by using only three different weight values: –1, 0, and 1. And the output from a neuron is either 0 or 1. It fires or it doesn’t. There are no gradients to descend, only discrete steps.
One key development reported in the PNAS paper is a series of tricks for making backpropagation work with spiking networks. The researchers solved the problem by training a software model of the chip, a model that was programmed to use approximations of the hardware that were still compatible with gradient descent. Throughout training, they kept two sets of synaptic strengths, a low precision set (with values of –1, 0, or 1) and a “hidden” high-precision set. Let’s say during training a synapse has a high-precision weight of 0.51, which means it has a low-precision weight of 1 (0.51 rounded up). An input will pass through and use 1, and once the final error is calculated, gradient descent will see if this synaptic weight needs to be higher or lower than 0.51. If higher, the high-precision weight goes to (say) 0.61 and the low-precision weight stays at 1. If lower, the high-precision weight goes to (say) 0.41 and the low-precision weight goes to 0. Once training is complete, the low- precision weights are programmed into the chip. “The crux of the innovation,” Modha says, “was that our team was able to incorporate neuromorphic constraints of energy, speed, and area into deep learning algorithms while learning offline"—using that simulation—“thus enabling later online inference on TrueNorth.”
Another key development was the mapping of CNNs with many connections per neuron onto a chip that allows only 256 connections per neuron. They did this in part by assigning certain pairs of neurons to represent one better-connected neuron, pooling their inputs and outputs and firing together.
To test the CNNs running on their chips, they trained them on eight commonly used data sets, comprising natural and artificial objects, house addresses, traffic signs, corporate logos, voice presence, and English phonemes. Using one chip, accuracy came within a few percentage points of the top results in the machine learning field. And they showed that eight tiled chips would nearly match or even outperform the state of the art. Further, it would do it at 2,600 images per second, using less than a third of a watt. Direct comparisons between systems on efficiency is tough, but Modha says TrueNorth beats its competitors by orders of magnitude.
Backpropagation is a key learning strategy for many types of neural networks, not just CNNs. So the method for adapting backprop to spiking nets (those with neurons that send a 0 or 1, implemented either in hardware or software) could have a much wider application in deep learning. IBM first described its method at a conference in December of 2015, alongside a group from Montreal presenting a similar method called BinaryConnect and a group from Zurich presenting a method called dual-copy rounding. Since then, there has been a lot of interest in modifying backprop to work with low-precision networks, according to Paul Merolla, a lead researcher on the TrueNorth project. “I count around 18 papers that have been published since [then],” he said in November 2016. "It is an exciting time for this field!”
The new neuromorphic
Despite TrueNorth’s performance, it wasn’t built with CNNs in mind, so it has several drawbacks compared with other systems now in development. As one researcher e-mailed, “The IBM TrueNorth chip is a marvelous piece of technology. But its design was made before the recent wave of DNNs (deep neural networks) and CNNs, so it was not optimized for those types of networks. This is, for example, evidenced by the fact that they need to use 8 chips (8 million neurons) to implement a network that uses only about 30 thousand neurons.” This same researcher notes other factors that make TrueNorth less neuromorphic than some other chips. For example, TrueNorth is completely digital, whereas some chips have analog components, which are more unpredictable but more efficient. (Biology is mostly analog.) And while each chip is divided into 4,096 “cores” that run in parallel, the 256 neurons within each core are updated only serially—one at a time.
Yu-Hsin Chen, an MIT researcher designing a chip called Eyeriss that’s optimized to run CNNs efficiently, recognizes TrueNorth isn't perfect but has potential for the emerging field. “Currently, they have only shown results for small datasets, instead of the state-of-the-art ones like the ImageNet dataset, and there’s already some accuracy hit. However, I’m still looking forward to their future progress," he says. “It’s very exciting to see how researchers are pushing boundaries from different routes.”
Any design choice creates a tradeoff. That serial processing of neurons in a TrueNorth core may create a bottleneck, but it provides regularity, and it means that
the chip’s behavior can be simulated with fidelity on desktop machines. “By choosing a digital, asynchronous design style,” Delbruck says, “they could make the hardware do one-for-one the same as a simulator, which allowed them to much more easily design applications than was possible for other systems—particularly mixed [analog-digital] signal systems.”
Modha notes that TrueNorth has accomplished a lot in spite of its drawbacks. “It was widely believed that given these constraints, it was impossible to implement deep learning inference on TrueNorth efficiently and effectively,” he says. “The Proceedings of the National Academy of Sciences study shows the neural networks are fundamentally very robust structures. The beauty of our work is that it indicates the versatility and generality of the TrueNorth neuromorphic substrate and platform—that we were able to implement convolution networks even though we had designed the chip as a priority”—without CNNs in mind.
That versatility means it can support many different types of networks, and Modha’s current goal is to implement several different networks side by side on a large TrueNorth system. This “compositionality,” as he calls it, would allow “complex multifaceted behavior. And that’s where we are headed.” The compositionality Modha’s team aims for may have biological validity. “One can argue,” he says, “the brain is indeed a composition of many networks working together in harmony.”
I asked Modha if TrueNorth provides any insight into neuroscience or if it's just an engineering tool loosely cribbing from the brain. He noted that in loading photos into the system, they had to convert the rich color images into a series of simple spikes for the chip to process. “This transduction process got us very excited,” he said. "We could begin to see how the brain itself might be representing high-fidelity information without high resolution.” More generally, he said, “as we try to represent very effective neural networks efficiently with regard to energy, time, and area, we
are forced to think how the brain must have evolved to be hardware efficient at the same time as task effective.” And noting in general the role of engineering in science, he quoted Richard Feynman: “What I cannot create I do not understand.”
North, on the up and up
In addition to achieving compositionality—different types of networks working together—Modha’s team aims to explore different training methods. Looking ahead, they would also like to see the methods reported in their PNAS paper adopted more widely; they note in the paper that they could be applied to neuromorphic chips other than TrueNorth. And they hope to see algorithms and chips co-designed, rather than forcing one to adapt to the other.
A 2015 Department of Energy report on neuromorphic computing pushed for more radical advances, perhaps involving the development of materials with new physical properties. The DOE wants better network speed, efficiency, and fault-tolerance. It notes that “currently, about 5-15 percent of the world’s energy is spent in some form of data manipulation, transmission, or processing.”
The aim of the field is to replace giant data centers with chips in our phones, homes, and cars that can think for themselves—carrying on conversations, making scientific and medical discoveries, operating automobiles or robots or prosthetic limbs. Ideally, these chips can achieve even greater successes, like solving world hunger.
A few labs have already reported how they’re putting TrueNorth to use. Last August, Samsung demonstrated a system that uses video to map its environment, in three dimensions, at 2,000 frames per second, using a third of a watt. They used it to control a television with hand gestures. Lawrence Livermore National Laboratory has a 16-chip board it is using to improve cybersecurity and ensure the safety of our nuclear weapons. And the Air Force Research Laboratory, which is using TrueNorth to give drones autonomous navigation, just announced a plan to try out a 64-chip array.
Roughly following Moore’s law, engineers continue to make transistors smaller, but they're approaching physical boundaries on the atomic scale. By using parallel processing and disbanding with unnecessary precision, neuromorphic computing may be a way around that limitation. “As we look to the next generation” of devices, Modha says, “it is our goal to push fundamental limits in time, space, and energy.” Look forward to a brain in a pocket near you.
As a Partner and Co-Founder of Predictiv and PredictivAsia, Jon specializes in management performance and organizational effectiveness for both domestic and international clients. He is an editor and author whose works include Invisible Advantage: How Intangilbles are Driving Business Performance. Learn more...




















0 comments:
Post a Comment