To Understand Digital Advertising, Study Its Algorithms
Data in, behavior out. JL
The Economist reports:
The "Turing Box ” is a piece of software. Place an algorithm in it, control
the data inputs, measure the outcomes, and work out how it behaves. To
study an algorithm upload it to a Turing box. The box’s software runs the algorithm through a data set of
the kind it was designed to crunch. Understanding algorithms’ behavior is urgent in digital-advertising, in which users of
software are in their own Skinner boxes— their actions monitored, and tailored rewards fed to them. ALAN MISLOVE studies algorithms. Recently, his research at Northeastern University, in Boston, has shown that Facebook’s software was leaking users’ phone numbers to advertisers. He has also found new ways to audit that same software for racial bias. But work like his faces challenges. Scraping data from public-facing websites often sails close to breaching their terms and conditions. And the companies those websites belong to are generally unwilling to give researchers more direct access to their systems.
Moreover, examining other people’s algorithms requires the creation of your own to do so. Dr Mislove’s group often spends months just writing the code needed to gather any data at all about the objects of its inquiry. This means that only those with sufficient computer-science skills can study the computer programs that play an ever-growing role in society—not just in commerce, but also in politics, economics, justice and many other areas of life. This is bad for research and for the public.
Now, as Facebook finds itself in the throes of a scandal over its handling of data and the power of its hyper-targeted advertising software, Dr Mislove is working with a group of researchers at the Massachusetts Institute of Technology (MIT) who think they have an answer to these problems. This group, based at MIT's Media Lab and led by Iyad Rahwan, has taken a leaf out of the book of B.F. Skinner, an animal behaviourist who, several decades ago, worked down the road from MIT at Harvard. Skinner invented a device, now known as a Skinner box, which standardised the process of behavioural experimentation. He used his boxes to control input stimuli (food, light, sound, pain) and then observed output behaviour in an attempt to link the one to the other. Though by no means perfect, the Skinner box was a big advance in the field. Dr Rahwan hopes to do something similar to software using what he calls a Turing box.
This “box” is itself a piece of software. Place an algorithm in it, control the data inputs, measure the outcomes, and you will be able to work out exactly how it behaves in different circumstances. Anyone who wants to study an algorithm could upload it to a Turing box. The box’s software would then start running the algorithm through a standard data set of the kind it was designed to crunch. All face-recognition algorithms, for example, would be given the same scientifically validated set of faces. The algorithm’s output—in this case how it classifies different faces—would be recorded and analysed. Dr Rahwan’s hope is that companies will want political and social scientists to use the box to scrutinise their algorithms for potentially harmful flaws (eg, treating faces differently on racial grounds), and that researchers will line up to do the testing.
Indeed, his ambitions go further still. His intention is that the Turing box should become just one component of a new field, the scientific study of the behaviour exhibited by intelligent machines, and of the impact of that behaviour on people. A demonstration paper he and his colleagues have submitted for publication to the International Joint Conference on Artificial Intelligence describes the system, as well as the broader details of this new field of machine behaviour. He plans to finish the Turing-box software by the summer, and says he will publish the code under an open-source licence shortly thereafter, for anyone to reuse. The running of the platform will then be left to a not-for-profit firm that he plans to spin out of MIT.
Boxing clever
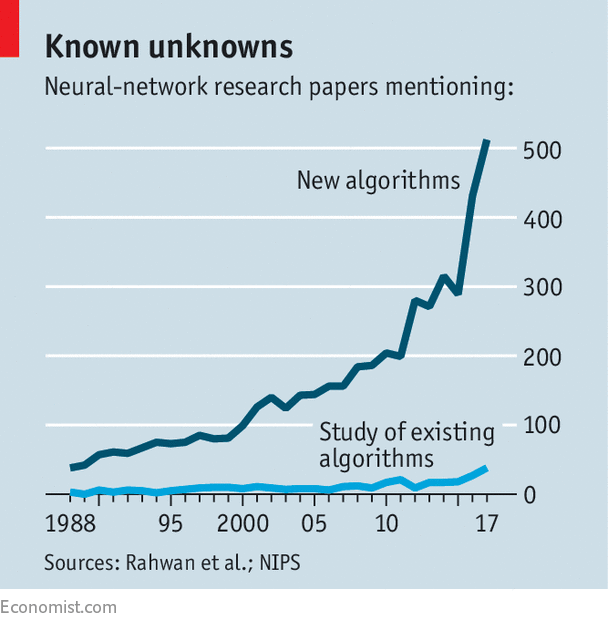
It is a neat idea, and timely. Algorithms are being developed far faster than their impacts are being studied and understood (see chart). The Turing box, if it works as intended, could help turn the tide. Understanding algorithms’ behaviour is particularly urgent in the existing digital-advertising “ecosystem”, in which individual users of software are, in effect, in their own Skinner boxes—with their actions constantly monitored, and tailored rewards fed to them. The Facebook furore, for example, revolves around allegations that Cambridge Analytica, a digital lobbying firm, improperly obtained data from Facebook, then used them to aim advertisements which influenced the American presidential election in 2016 (the firm has denied any wrongdoing).
Dr Rahwan recognises that the reluctance of many companies which form part of the digital-advertising ecosystem to upload their algorithms for inspection make it a bad place to start. So, to begin with, he will work elsewhere, studying less controversial and commercially sensitive systems such as open-source algorithms for processing natural language.
He says, though, that the ultimate goal is to enable the study of the algorithms which some of the world’s most valuable IT firms hold dearest: Facebook’s newsfeed, for example, or Amazon’s product-recommendation software. That means looking at the behaviour of these algorithms in an environment which is as close as possible to that in which they normally operate, so that their impact on the real world can be measured. This in turn will require the firms that own them giving independent researchers access to their systems and data.
Recent years have seen things go in the opposite direction. According to Michal Kosinski of the Stanford Graduate School of Business, who in 2012 pioneered the use of Facebook data to study personality, “academic researchers have virtually no access even to publicly available data without breaking a given platform’s terms of service.” Firms’ scruples in these matters are not driven only by desire for commercial secrecy. As this week’s events have shown, a leak of personal data from an academic inquiry can be just as damaging as one from a sloppy business partner.
So, research on particularly sensitive data may require academics to be physically present inside an organisation in order to gain access to those data, a process akin to studying in the rare-books section of a library. It might also be a good idea to have independent umpires of some sort, to ensure that both firms and researchers stay on the straight and narrow.
Facebook seems open to the idea of working with researchers in this way. In a statement given to The Economist a few days before the Cambridge Analytica story broke, the firm stated a desire to work with researchers in order to understand the impact of its systems, but warned that it had to shield its users’ data from third parties. Facebook also said that it is “actively working” on an approach which achieves both goals, although it declined to provide any details of that work. Contacted later in the week, the firm’s data-science team declined to issue any additional statement.
The Turing box is only in the earliest stages of development, but it, and systems like it, offer to inject something vital into the discussion of digital practices—independently gathered causal evidence. Without that, people may never get out of the Skinner boxes in which the tech firms have put them.
As a Partner and Co-Founder of Predictiv and PredictivAsia, Jon specializes in management performance and organizational effectiveness for both domestic and international clients. He is an editor and author whose works include Invisible Advantage: How Intangilbles are Driving Business Performance. Learn more...



















0 comments:
Post a Comment