Greek AI 2 to 4 Times More Accurate At Asymptomatic Travellers To Test For Covid
During peak tourist season, the AI system successfully identified 2 to 4 times more asymptomatic travelers than did random testing. JL
Ziad Obermeyer reports in Nature:
Between August and November 2020, Greek authorities launched a system that uses a
machine-learning algorithm to determine which travellers entering the
country should be tested for COVID-19. The authors found machine
learning to be more effective at identifying asymptomatic people than
was random testing or testing based on a traveller’s country of origin. During the peak tourist season,
the system detected two to four times more infected travellers than did
random testing.
It seems an obvious combination: machine learning and the fight against COVID-19. And yet, despite intense interest and increasing availability of large data sets, success stories of such combinations are few and far between.Writing inNature, Bastaniet al.1describe a system that they designed and deployed at points of entry into Greece, starting in August 2020. The algorithm, which is built on a method called reinforcement learning, markedly increased the efficiency of testing for the coronavirus SARS-CoV-2, and contributed to Greece’s ability to keep its borders open safely. The work also provides a clear warning about the shortcomings of the comparatively blunt policy tools that most other countries continue to use.
Testing is a problem that machine learning is well suited to solve. Imagine a border-control agent on a Greek island. A flight has just landed, and the agent’s task is to identify and detain anyone who has COVID-19. The agent might want to test all arriving passengers, but the testing capacity on the island is very limited and, more generally, it is never possible to test 100% of any population 100% of the time. The alternative — shutting down the border completely, in an economy highly dependent on tourism — has its own perils. These would include not only a huge financial cost associated with the loss of jobs and income, but also the negative effects of such losses on public health2. So the border agent faces a difficult decision: who should be tested?
As has been noted3, the value of a test depends on its eventual outcome. In this scenario, a negative test generates only costs: the cost of testing and a delay for the traveller. By contrast, a positive test generates tremendous benefit: prevention of all the cases of COVID-19 that a traveller infected with SARS-CoV-2 would have caused. So, in deciding who to test, the border agent’s optimal strategy is clear: predict which travellers have the highest likelihood of testing positive, and test them. This strategy maximizes the value of testing, because it detects the most travellers with COVID-19 using the lowest number of tests.
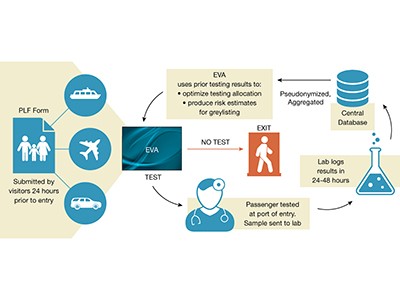
If the border agent could predict which incoming passengers are most likely to test positive, tests could be allocated efficiently (Fig. 1). Conveniently, data about incoming passengers — their country and region of origin, age and sex — are available digitally, on the passenger locator form that all travellers complete 24 hours before arrival in Greece. It seems straightforward enough to use data from past tests of incoming passengers to predict which ‘types’ of passenger might be more likely to test positive in the future. But, as decades of research in statistics and computer science have shown4, this strategy runs the risk of getting locked into yesterday’s pandemic: given the rapidly evolving dynamics of COVID-19 spread, an algorithm must quickly adapt its predictions to stay one step ahead and still test the right passengers.
Figure 1 | COVID-19 testing of travellers arriving at Eleftherios Venizelos International Airport in Athens.Credit: Milos Bicanski/Getty
This is where the value of machine learning becomes clear. Just as an algorithm can be trained to play the game Go5by learning which moves lead to winning the game, Bastani and colleagues trained an algorithm to allocate scarce tests, by learning which passengers are likely to test positive.
Crucially, the algorithm balances two goals. The first, and most natural, goal is to test passenger types who are likely to test positive, by exploiting patterns learnt from previous data about the outcome of tests for SARS-CoV-2 in these different groups. The second — perhaps less intuitive, but equally important — is to explore patterns not reflected in previous data, by testing passenger types about which the algorithm knows little.
Then, at a given port of entry on a given day, the algorithm delivers targeted recommendations to border agents about which passengers to test, while respecting the budget and resource constraints imposed by supply chains, staffing, laboratory capacity and delivery logistics for biological samples. These constraints are real and binding: the authors note that, at the peak of the summer tourism season, there was capacity to test only 18.4% of incoming travellers — even after the Greek National COVID-19 Committee of Experts wisely approved group testing to drive efficiency gains in the lab.
The authors draw on the reinforcement-learning strategies that have powered advances in online commerce and marketing6. But using such an algorithm in the real world raises its own technical challenges. For example, the algorithm must learn discontinuously, from large batches of testing results, rather than one-by-one from individual results. And the feedback from batch results is delayed, forcing the algorithm to operate uninformed while waiting for results. Solving these challenges required substantial tweaking of the algorithms that are typically designed for easier, more data-rich online settings.
The thorniest challenges, however, are legal and political ones. To comply with the European Union’s General Data Protection Regulation (GDPR), the authors deliberately limited the data available to the algorithm — and thus its accuracy — in close consultation with lawyers, epidemiologists and policymakers. The potential limit placed on the algorithm’s performance by the GDPR highlights how well-intentioned laws to protect privacy can have both positive and negative consequences. In a pandemic that does not respect individuals’ privacy, such regulations can ultimately hamper the ability of a government to protect the health of its citizens. The authors also adapted the algorithm with a policymaker audience in mind, choosing their optimization methods to showcase clearly the value of both algorithm goals: testing high-risk passengers and testing high-uncertainty passengers.
The results are impressive. The automated system doubled the efficiency of testing — the number of cases detected per test — allowing border agents to test and quarantine the right passengers, many of whom were asymptomatic, while letting others through to their final destination.
The success of the algorithm presented by Bastani and colleagues highlights the inadequacy of the border policies of nearly all other countries. The decisions underlying these policies — for example, whether to deny all travellers entry to the country or to force the testing or quarantine of all travellers from a given country — have two key flaws. First, these decisions are made about entire countries, rather than individuals, disregarding vast differences between people within countries. Second, they are typically made on the basis of country-level epidemiological data that, as the present study shows, have notable shortcomings.
Had border agents denied entry to all passengers from countries that had concerning metrics, they would have prevented those people with COVID-19 from entering Greece — but at the cost of crushing a key pillar of the economy. Had they simply tested people proportional to a country’s reported COVID-19 metrics rather than algorithmic predictions, however, their testing efficiency would have been much lower. This is because reported COVID-19 metrics can be very different from actual disease prevalence among incoming travellers. Travellers are not randomly drawn from their countries’ populations, and passively collected data on cases of COVID-19 or deaths associated with the disease reflect large reporting biases and systemic barriers to access7.
Indeed, by efficiently testing incoming passengers, the authors’ algorithm was able to anticipate spikes in SARS-CoV-2 infection rates among traveller populations almost 9 days earlier than if they had used country-level epidemiological data alone. This indicates the enormous value of intelligent, deliberate data collection — and the dangers of relying on blunt, flawed, country-level data for important decisions.
Bastani and colleagues’ work will be remembered as one of the best examples of using data in the fight against COVID-19. It is a compelling story of how a group of researchers partnered with enlightened policymakers to produce a tool that has enormous social value. It highlights the best parts of both academic research and the civil service, and shows the great promise of artificial intelligence for making good decisions — which in many settings can be the difference between life and death.
As a Partner and Co-Founder of Predictiv and PredictivAsia, Jon specializes in management performance and organizational effectiveness for both domestic and international clients. He is an editor and author whose works include Invisible Advantage: How Intangilbles are Driving Business Performance. Learn more...




















0 comments:
Post a Comment