Definitely easier than actually becoming a data scientist. JL
Conor Lazarou reports in Towards Data Science:
These days it seems like everyone and their dog are marketing themselves
as data scientists—and you can hardly blame them, with “data scientist”
being declared theSexiest Job of the Centuryand carrying the salary to boot. Laypeople think machine learning is all about black boxes that
magically churn out results from raw data; please don’t contribute to
this misconception. I’ve compiled this list of tells so if you’re a hiring manager and don’t know what you’re looking for, you can filter out the slag, and if you’re an aspiring
data scientist, you can fix them
before you turn into a poser yourself.
These days it seems like everyone and their dog are marketing themselves as data scientists—and you can hardly blame them, with “data scientist” being declared theSexiest Job of the Centuryand carrying the salary to boot. Still, blame them we will, since many of these posers grift their way from company to company despite having little or no practical experience and even less of a theoretical foundation. In my experiences interviewing and collaborating with current and prospective data scientists, I’ve found a handful of tells that separate the posers from the genuine articles. I don’t mean to belittle self-taught and aspiring data scientists — in fact, I think this field is especially appropriate for passionate self-learners —but Idefinitelymean to belittle the sort of person who takes a single online course and ever after styles themselves an expert, despite having no knowledge of (or interest in) the fundamentaltheoryof the field. I’ve compiled this list of tells so that, if you’re a hiring manager and don’t know what you’re looking for in a data scientist, you can filter out the slag, and if you’re an aspiring data scientist and any of these resonate with you, you can fix them before you turn into a poser yourself. Here are three broad domains of data sciencefaux paswith specific examples that will land your resume in the bin.
1. You Don’t Bother with Data Exploration
Data exploration is the first step in any machine learning project. If you don’t take the time to familiarize yourself with your data and get well-acquainted with its features and quirks, you’re going to waste a significant amount of time barking up the wrong decision tree before arriving at a usable product — if you even make it there.
A) You don’t visualize your data
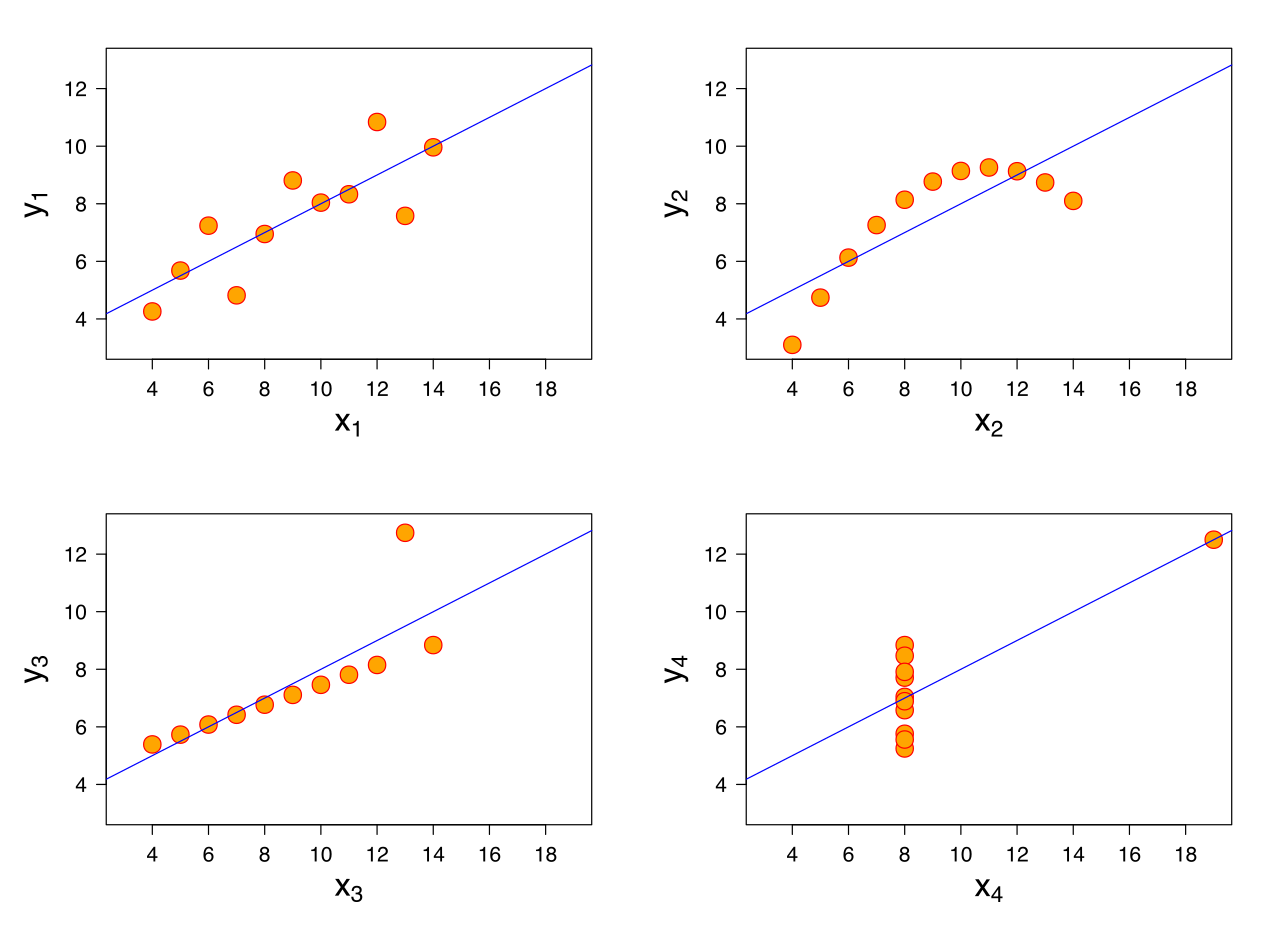
Exploratory data visualization is the best way to start any data-related project. If you’re applying machine learning, it’s likely that you’re working with a high volume of high-dimensional data; perusing a .csv in Excel or running adf.describe()is not a suitable alternative to proper data visualization. Francis Anscombe illustrated the importance of data visualization with his famous quartet:
The datasets in each panelall have essentially identical summary statistics: thexandymeans,xandysample variances, correlation coefficients, R-squared values, and lines of best fit are all (nearly) identical. If you don’t visualize your data and rely on summary stats, you might think these four datasets have the same distribution, when a cursory glance shows that this is obviously not the case.
Data visualization allows you to identify trends, artifacts, outliers, and distributions in your data; if you skip this step, you might as well do the rest of the project blindfolded, too.
B) You don’t clean your data
Data is messy: values get entered wrong; conversions run awry; sensors go spastic. It’s important that you resolve these issues before you waste months and months on a dead-end project, and it’s mission critical that you resolve them before pushing your models to production. Remember:garbage in ⇒ garbage out.
There are lots of good ways to identify problems with your data and no good ways to identify them all. Data visualization is a good first step (have I mentioned this?), and although it can be a tedious and manual process it pays for itself many times over. Other methods include automatic outlier detection and conditional summary stats.
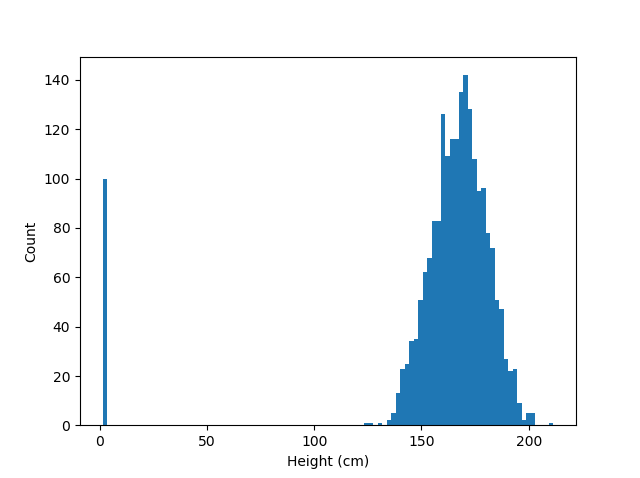
For an example, consider this histogram of human heights:
A histogram of adult human heights
Training a model with this data would doubtless lead to poor results. But, by inspecting the data, we find that the 100 “outliers” in fact had their height entered in metres rather than centimetres. This can be correcting by multiplying these values by 100. Properly cleaning the data not only prevents the model from being trained on bad data, but, in this case, let us salvage 100 data points that might otherwise have been thrown out. If you don’t clean your data properly, you’re leaving money on the table at best and building a defective model at worst.
C) You don’t bother with feature selection and engineering
One of the cool things about neural networks is that you can often throw all your raw data at it and it will learn some approximation of your target function. Sorry, typo, I meantone of theworstthings. It’s convenient, sure, but inefficient and brittle. Worst of all, it makes beginner data scientists reliant on deep learning when it’s often the case that a more traditional machine learning approach would be appropriate, sending them on a slow descent to poserdom. There’s no “right” way to do feature selection and engineering, but there are a few key outcomes to strive for:
Dimensionality Reduction: More data isn’t always better. Often, you want to reduce the number of features before fitting your model. This typically involves removing irrelevant and redundant data, or combining multiple related fields into one.
Data Formatting: Computers are dumb. You need to convert your data into a format that your model will easily understand: neural networks like numbers between -1 and 1; categorical data should be one-hot encoded; ordinal data (probably) shouldn’t be represented as a single floating point field; it may be beneficial to log transform your exponentially-distributed data. Suffice it to say, there’s a lot of model-dependent nuance in data formatting.
Creating Domain-Specific Features:It’s often productive to create your own features from data. If you have count data, you may want to convert it into a relevant binary threshold field, such as “≥100” vs “<100 0="" continuous="" data="" have="" if="" is="" not="" or="" span="" vs="" you="">
xandz, you may want to include fieldsx²,xz, andz²alongsidexandzin your feature set. This is a highly problem-dependent practice, but if done right can drastically improve model performance for some types of models.
Most laypeople think that machine learning is all about black boxes that magically churn out results from raw data; please don’t contribute to this misconception.
2: You Fail to Choose an Appropriate Model Type
Machine learning is a broad field with a rich history, and for much of that history it went by the name “statistical learning”. With the advent of easy-to-use open source machine learning tools like Scikit-Learn and TensorFlow, combined with the deluge of data we now collect and a ubiquity of fast computers, it’s never been easier to experiment with different ML model types. However, it’s not a coincidence that removing the requirement that ML practitionersactually understandhow different model types work has led to many ML practitionersnot understandinghow different model types work.
A) You just try everything
The github repos of aspiring data scientists are littered with Kaggle projects and online course assignments-come-portfolios that look like this:
from sklearn import *
for m in [SGDClassifier, LogisticRegression, KNeighborsClassifier,
KMeans, KNeighborsClassifier, RandomForestClassifier]:
m.overfit(X_train, y_train)
This is an obvious giveaway that you don’t understand what you’re doing. It’s a waste of time and easily leads to inappropriate model types being selected because they happened to work well on the validation data (you remembered to hold out a validation set, right?Right?). The type of model used should be selected based on the underlying data and the needs of the application, and the data should be engineered to match the chosen model. Selecting a model type is an important part of the data science process, and direct comparison between a handful of appropriate models may be warranted, but blindly applying every tool you can in order to find the one with “the best number” is a major red flag. In particular, this belies an underlying problem which is that…
B) You don’t actually understand how different model types work
Why might a KNN classifier not work so well if your inputs are “car age in years” and “kilometres traveled”? What’s the problem with applying linear regression to predict global population growth? Why isn’t my random forest classifier working on my dataset with a 1000-category one-hot-encoded variable? If you can’t answer those questions, that’s okay! There are lots of great resources to learn how each of these techniques work; just be sure to read and understand thembeforeyou apply for a job in the field.
The bigger problem here isn’t that people don’t know how different ML models work, it’s that they don’t care and aren’t interested in the underlying math. If you like machine learning but don’t like math, you don’t really like machine learning;you have a crush on what youthinkit is. If you don’t care to learn how models work or are fit to data, then you’ll have no hope of troubleshooting them when they inevitably go awry. The problem is only exacerbated when…
C) You don’t know if you want accuracy or interpretability, or why you have to pick
All model types have their pros and cons. An important trade-off in machine learning is that between accuracy and interpretability. You can have a model that does a poor job of making predictions but is easy to understand and effectively explains the process, you can have a black box which is very accurate but whose inner workings are an enigma, or you can land somewhere in the middle.
Which type of model you choose should be informed by which of these two traits is more important for your application. If the intent is to model the data and gain actionable insights, then an interpretable model, such as a decision tree or linear regression, is the obvious choice. If the application is production-level prediction such as image annotation, then interpretability takes a backseat to accuracy and a random forest or neural network is likely more appropriate.
In my experience, data scientists who don’t understand this trade-off and those who beeline for accuracy without even considering why interpretability matters are not the sort you want training models for you.
3: You Don’t Use Effective Metrics and Controls
Despite making up 50% of the words and 64% of the letters, the “science” component of data science is often ignored. It’s not uncommon for poser data scientists to blindly apply a single metric in a vacuum as their model evaluation. Unwitting stakeholders are easily wowed by bold claims like “90% accuracy” which aretechnicallycorrect but wildly inappropriate for the task at hand.
A) You don’t establish a baseline model
I have a test for pancreatic cancer which is over 99% accurate. Incredible, right? Well, it’s true, and you can try it for yourself by clickingthis link.
If you saw a red circle with a line through it, you’ve tested negative. If you saw a green check mark, you’re lying. The point is, 99% of people don’t have pancreatic cancer (more, actually, but let’s just assume it’s 99% for the sake of this example), so my silly little “test” is accurate 99% of the time. Therefore, if accuracy is what we care about, any machine learning model used for diagnosing pancreatic cancer should performat least as wellas this uninformative, baseline model. If the hotshot you’ve hired fresh out of college claims he’s developed a tool with 95% accuracy, compare those results to a baseline model and make sure his model is performing better than chance.
B) You use the wrong metric
Continuing the diagnostic example above, it’s important to make sure you’re using the right metric. For cancer diagnosis, accuracy is actually a bad metric; it’s often preferable todecreaseyour accuracy if it means an increase in sensitivity. What’s the cost associated with a false positive? Patient stress, as well as wasted time and resources. What’s the cost of a false negative? Death. An understanding of the real-world implications of your model and an appreciation of how those implications govern metric selection clearly delineate real data scientists from their script-kiddie lookalikes.
C) You bungle the train/test split
This is a big one, and it’s far too common. Properly testing a model is absolutely essential to the data science process. There are many ways this can go awry: not understanding the difference between validation and test data, performing data augmentation before splitting, not plugging data leaks, ignoring data splitting altogether… There’s not much to say about this other than that if you don’t know or care how to create a proper holdout set, all your work has been a waste of time.
…to import tensorflow as tf
These are only a handful of tells that give up the game. With enough experience, they’re easy to spot, but if you’re just starting out in the field it can be hard to separate theSiraj Ravalsof the world from the Andrew Ngs. Now, I don’t mean to gatekeep the field to aspiring data scientists; if you feel attacked by any of the above examples, I’m glad to hear it becauseit means you care about getting things right. Keep studying, keep climbing so that you too can be endlessly irked by the sea of posers.
As a Partner and Co-Founder of Predictiv and PredictivAsia, Jon specializes in management performance and organizational effectiveness for both domestic and international clients. He is an editor and author whose works include Invisible Advantage: How Intangilbles are Driving Business Performance. Learn more...






















0 comments:
Post a Comment